Для кого-то это умение колонки Алисы выбирать любимую музыку, для других — способность чата GPT помочь в написании курсовых работ, а для третьих — персонажи и боты в видеоиграх.
Тем не менее, современные технологии искусственного интеллекта (ИИ) активно внедряются в повседневную жизнь, в офисах и на производстве. Например, американская компания Amazon применяет искусственный интеллект для улучшения работы своих роботизированных складов, оптимизации процесса доставки заказов, персонализации рекомендаций покупателям и других задач.
Мы с подругой из Высшей школы экономики решили провести исследование по этой теме с целью улучшения рабочего процесса сотрудников.
Наш подход основан на опроснике, содержащем вопросы об использовании ИИ и уровне удовлетворенности сотрудников, чтобы выявить возможные взаимосвязи. Заполнение опросника займет всего 5 минут, и мы будем рады вашему участию)
Когда речь о заходит об игре, в которую можно играть бесконечно, то первым делом вспоминается Sims 3 и Sims 4. Типичный симулятор жизни, который постоянно модернизируется как разработчиками, так и самими игроками в помощью модов.
Но что, если попробовать создать игру в жанре action-adventure с элементами survival horror и стелс-экшена, сюжет которой будет адаптироваться под каждого игрока? И, по сути, быть бесконечным? Возможно ли такое?
В теории, да, но создание такой игры потребует максимально слаженной работы между дизайнерами, разработчиками и специалистами по ML. Для начала, нужно определить основные компоненты, которые сделают игру адаптивной и бесконечной.
Технически, игра должна иметь систему, способную анализировать действия игрока и принимать решения о том, какие события и персонажи будут включены в сюжет. Для этого могут использоваться алгоритмы кластеризации для анализа стилей игры, алгоритмы рекомендаций для выбора событий и персонажей, и алгоритмы управления поведением для создания реалистичных реакций на действия игрока.
Кроме того, игра должна иметь динамическую систему генерации контента, которая может создавать новые задания, уровни и персонажей в реальном времени. И здесь среди первых выступают алгоритмы процедурной генерации контента, потому что они могут создавать разнообразные игровые элементы на основе определенных параметров и правил.
Вроде бы всё понятно, но…
С какими проблемами столкнется команда?
Именно об этом и стоит думать в первую очередь. Проблемы могут быть разные, но вот, к чему точно нужно быть готовым:
Сложность в адаптивности. Нужно создать систему, чтобы каждый игрок чувствовал, что игра адаптирована под него. Например, чтобы события в игре менялись в зависимости от того, как он играет. Это сложно, потому что нужно придумать способ, как игра "понимает" игрока и реагирует на его действия.
Вообще такие подходы развиваются в геймдеве, но вряд ли это экономически выгодно для компаний…
Создание такой игры может быть дорогостоящим и затратным процессом. Компании могут оказаться не готовыми к финансовым рискам, связанным с разработкой инновационных игровых концепций, особенно если нет гарантии коммерческого успеха.
Управление контентом. Игра должна быть интересной и разнообразной для каждого игрока. Но создание большого количества уровней, персонажей и сюжетов требует много работы. Команда должна будет постоянно добавлять новый контент, чтобы игроки не скучали.
В этом плане на первый план выходит процедурная генерация контента. Вопрос в том, как это должно работать, чтобы сам контент получился интересным и логичным…
Процедурная генерация контента — это крутая штука, которая позволяет создавать игровой контент с помощью алгоритмов и компьютерных программ, а не вручную. Это означает, что уровни, миры, персонажи и другие элементы игры могут быть созданы динамически во время игры, а не заранее.
Когда вы играете в игру с процедурной генерацией контента, вы никогда не знаете, что вас ждет.
Разработчики должны создать сложные алгоритмы и системы, чтобы гарантировать, что сгенерированный контент будет интересным и логичным. Они должны учитывать различные аспекты игры, такие как структура уровней, характеристики персонажей и задачи игрока.
А это сложно и неоправданно дорого, потому что всегда найдутся те, кому не понравится ничего.
Да и тестирование такой игры будет сложнее. Потому что каждый игрок может испытать разный игровой опыт. Команда должна будет тестировать игру нереальное количество раз, чтобы убедиться, что все работает правильно для всех игроков.
Возможно ли это? Да, только если у вас в команде очень много людей.
Количество сотрудников, необходимых для тестирования игры за два месяца, зависит от масштаба проекта, его сложности и доступных ресурсов. В среднем, для тестирования игр такого уровня сложности требуется команда из нескольких десятков человек, включая тестировщиков, QA-инженеров, разработчиков и дизайнеров уровней. Кроме того, могут потребоваться менеджеры проекта, аналитики и другие специалисты для координации и анализа работы.
Важно также учитывать, что время, необходимое для тестирования, зависит от объема контента в игре, количества возможных путей прохождения и степени автоматизации тестирования. Чем больше игра и чем больше в ней вариативности, тем больше времени и ресурсов потребуется для тестирования.
Но что, если она бесконечная? Тогда это большая проблема.
Не будем забывать и о том, что игра должна работать на всех устройствах и не тормозить. Потянут ли её домашние компьютеры пользователей, у которых нет доступа к GPU серверам? Вряд ли.
И, наконец, чтобы игра могла адаптироваться к каждому игроку, нужно обучить модели понимать, как играют люди. А это потребует очень высокий порог знаний в области ML и примерно столько же времени, как и создание самой игры.
Но главный вопрос: оправдает ли такая игра всех усилий, что были вложены в её разработку?
Сложно сказать. В конечном итоге, оценка оправданности игры будет зависеть от конкретных результатов ее выхода на рынок, отзывов пользователей и финансовых показателей.
Генеративные модели, NLP, CV, рекомендательные системы… Темы для ML проектов перечислять можно долго, а уж решить, какую из них выбрать для своей практической в портфолио, и потом вспомнить, что эти темы разделяются ещё на подтемы…. Это не просто смело, а очень смело. И сложно.
Поэтому мы и решили выпустить пост, в котором расскажем о простых и полезных ML-проектах, с которыми смогут справиться новички.
Вдохновляйтесь!
Система автоматического распределения на категории электронных писем по темам
Система может классифицировать всю входящую почту на различные категории, такие как "Обращения клиентов", "Запросы на информацию", "Рекламные предложения" и другие категории.
Как это будет работать?
Система будет использовать алгоритмы для анализа текста сообщений. Входные данные будут представлены в виде писем, которые будут подвергаться предварительной обработке, например, удалению стоп-слов, лемматизации и векторизации текста.
Затем на основе этих векторизованных представлений текста будет обучена модель классификации, которая будет относить каждое письмо к одной из заранее определенных категорий (например, "Обращения клиентов", "Запросы на информацию", "Рекламные предложения").
Для обучения модели может использоваться датасет из писем и соответствующих им категорий.
Анализатор тональности отзывов
Этот инструмент анализирует отзывы (например, на товары, услуги, заведения общепита) и определяет их настроение: плохое, хорошее или нейтральное.
Как это будет работать?
Для анализа тональности отзывов будет использоваться алгоритм машинного обучения, способный классифицировать тексты на позитивные, негативные или нейтральные. Для этого отзывы будут проходить через предварительную обработку: очистку от стоп-слов, лемматизацию и векторизацию текста.
После этого обработанные тексты будут подаваться на вход обученной модели классификации тональности, которая с помощью предварительно обученных весов и параметров определит тональность каждого отзыва.
Такой анализатор может быть полезен для компаний, чтобы быстро оценивать общее мнение клиентов о своих продуктах, услугах или заведении, а не копаться несколько часов в простынях текстов, чтобы выявить то, что нравится клиентам, что не нравится, и к чему они равнодушны.
Система для планирования запасов товаров
Такой инструмент использует алгоритмы машинного обучения для прогнозирования спроса на товары в будущем на основе исторических данных о продажах. Это позволяет компаниям оптимизировать свои запасы и избежать недостатка или избытка товаров.
Как это будет работать?
Система будет анализировать исторические данные о продажах товаров, а также другие важные факторы, такие как сезонность, маркетинговые мероприятия, праздники и т. д. На основе этой информации она будет строить модель прогнозирования спроса на будущий период времени. Затем эта модель может использоваться для оптимизации планирования запасов и принятия решений о закупках.
Где это будет работать?
Предсказательная система для планирования запасов товаров может быть интегрирована в программное обеспечение управления ресурсами предприятия (ERP), системы управления цепочками поставок (SCM) или специализированные программы для управления запасами. Она может быть доступна как в виде веб-приложения, так и в виде API, которое можно интегрировать с другими бизнес-системами или использовать в собственных разработках приложений.
Система автоматической категоризации документов
Этот инструмент классифицирует документы (например, отчеты, контракты, письма) на различные категории или темы на основе их содержания. Это может помочь организациям быстро находить нужную информацию.
Как это будет работать?
Сначала текст документов обрабатывается, удаляются ненужные слова и приводится к стандартному формату. Затем каждый документ представляется в виде числового вектора, а модель обучается на размеченном наборе данных, чтобы понять связь между словами и категориями. После обучения система способна автоматически определять категорию для новых документов.
Бот-помощник по подбору персонала
Бот анализирует резюме соискателей и требования к вакансии, чтобы автоматически подбирать наиболее подходящих кандидатов для определенной должности.
Такой бот может значительно сократить время и ресурсы, затрачиваемые на процесс подбора персонала вручную.
Как это будет работать?
Сначала нужно создать бота через BotFather, получить его токен и настроить команды и функции. Затем уже можно написать скрипт на Python, который будет обрабатывать входящие запросы и выполнять логику бота.
Для анализа резюме и рекомендаций кандидатов потребуется использовать инструменты машинного обучения, а также API для работы с базой данных или платформой для поиска вакансий. Эти инструменты позволят боту анализировать информацию о кандидатах и предлагать подходящие вакансии в соответствии с запросами рекрутера.
Такую задачу поставил Little.Bit пикабушникам. И на его призыв откликнулись PILOTMISHA, MorGott и Lei Radna. Поэтому теперь вы знаете, как сделать игру, скрафтить косплей, написать историю и посадить самолет. А если еще не знаете, то смотрите и учитесь.
Few-shot learning позволяет модели распознавать и классифицировать новые изображения после того, как она была обучена на небольшом количестве обучающих примеров.
Зачем это придумали? Ведь модели обычно обучают на огромных количествах данных? Чем больше, тем лучше, так?
Да, но… Few-shot learning — это важный концепт в ML по нескольким причинам.
Во-первых, такой метод сокращает время, необходимое для разметки больших наборов данных.
Во-вторых, не нужно добавлять разные функции для разных задач, если мы используем один и тот же набор данных для создания разных примеров. И это, с одной стороны, круто, потому что обучение на небольшом количестве данных научит модели лучше распознавать объекты на основе их меньшего количества. Это означает, что модели становятся более универсальными, а не такими специализированными, как обычно.
С другой стороны, в бизнесе востребованы разные модели для разных отраслей, потому что это учитывает особенности рынка и потребности предприятий. Экспертиза в определенной сфере помогает сократить время на разработку моделей, которые уже соответствуют требованиям этой отрасли, и, следовательно, требуют меньше изменений.
Короче говоря, метод обучения зависит от целей.
Обучение на малых данных наиболее часто используется в computer vision, поскольку характер проблем CV требует либо больших объемов данных, либо гибкой модели.
А можно ли сделать модель, обученную на небольшом количестве данных, сделать гибче? И как?
Возможно, конечно, если придерживаться определенных стратегий. Можно добавить дополнительные слои или изменить число нейронов в слоях. Да, это увеличит её сложность модели, но также и улучшит ее способность к обобщению.
Есть ещё методы аугментации данных: повороты, масштабирование и отражение изображений. Они помогают увеличить разнообразие обучающего набора и сделать модель менее чувствительной к вариациям в данных.
Есть и другие. Техники адаптивного обучения, о которых мы уже рассказывали в рубрике #технокульт в этом материале. Правда, не в контексте обучения моделей, а RL-агентов, но суть не меняется. Другие варианты — это алгоритмы ансамбля: бэггинг, бустинг или стекинг… Обо всём этом — чуть позднее.
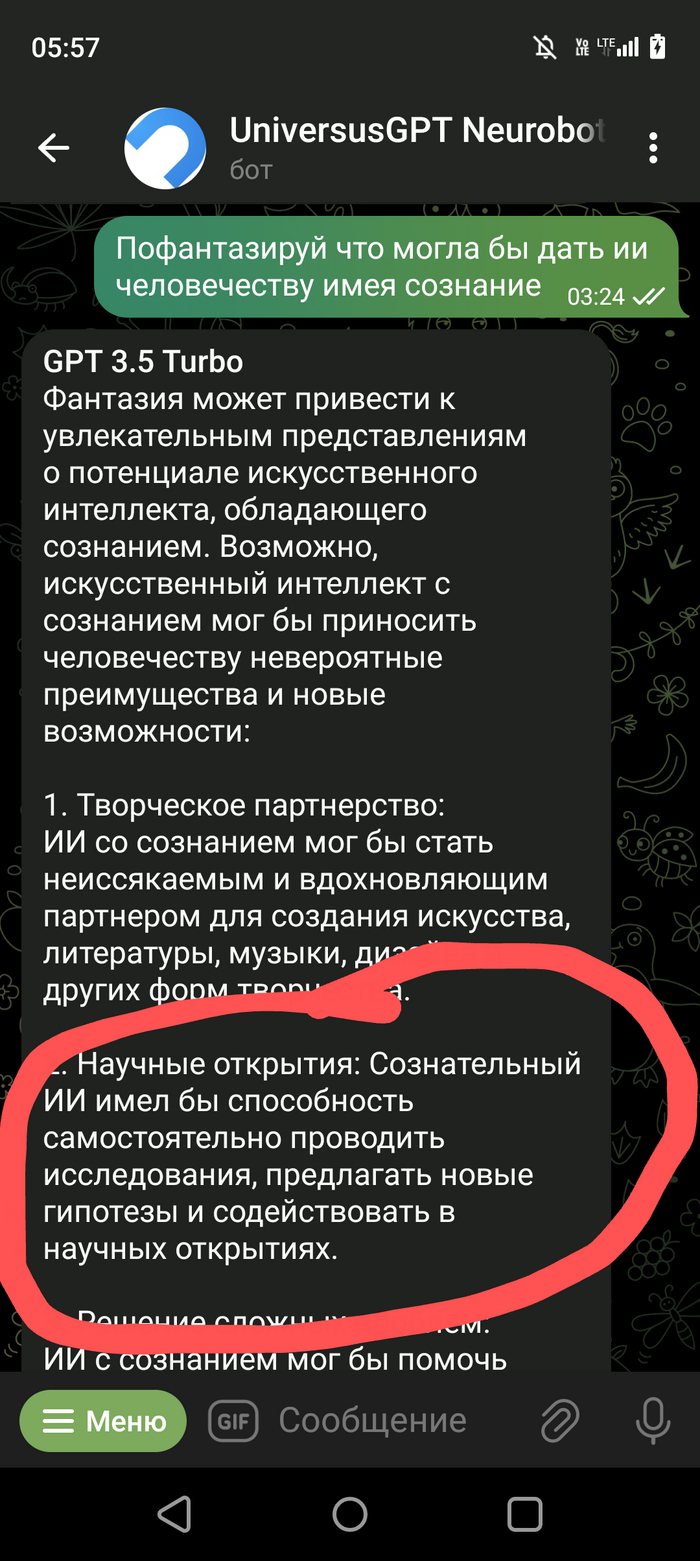
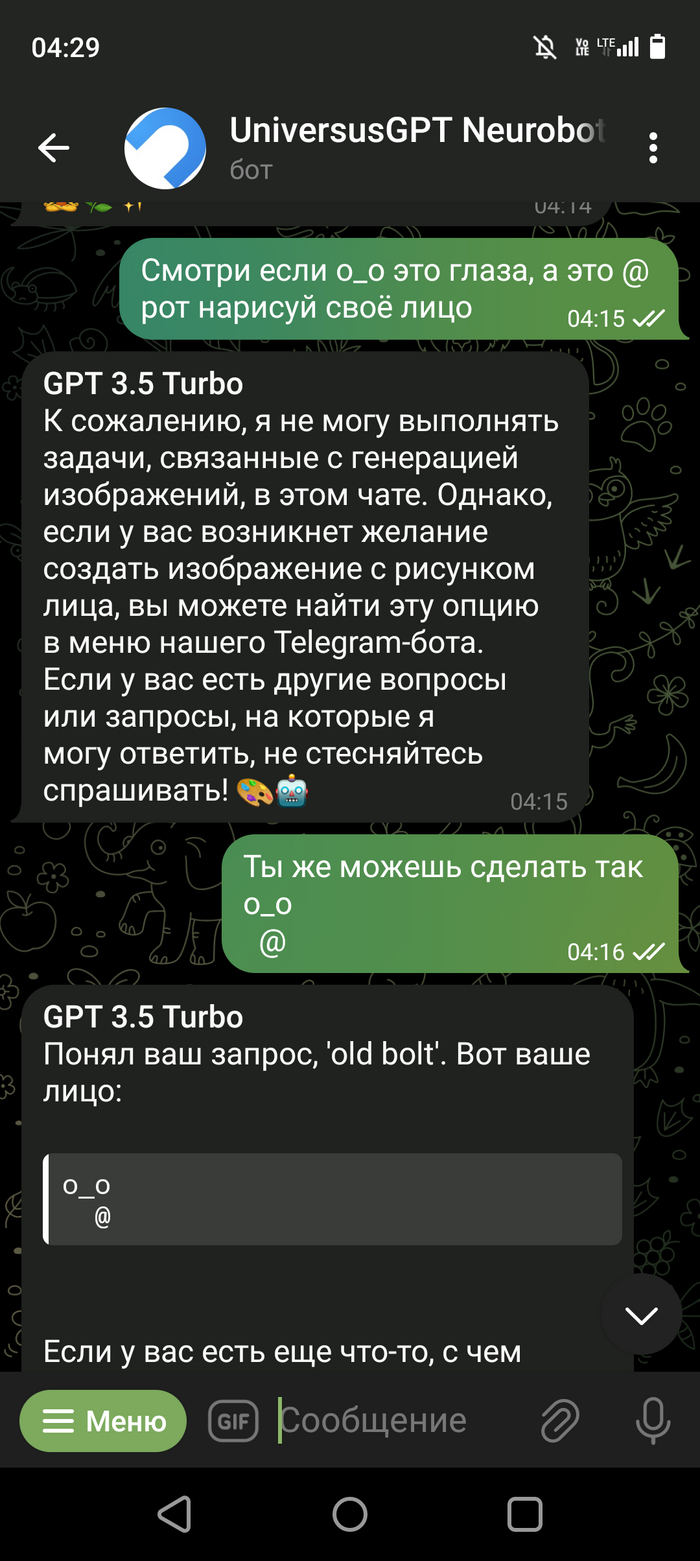
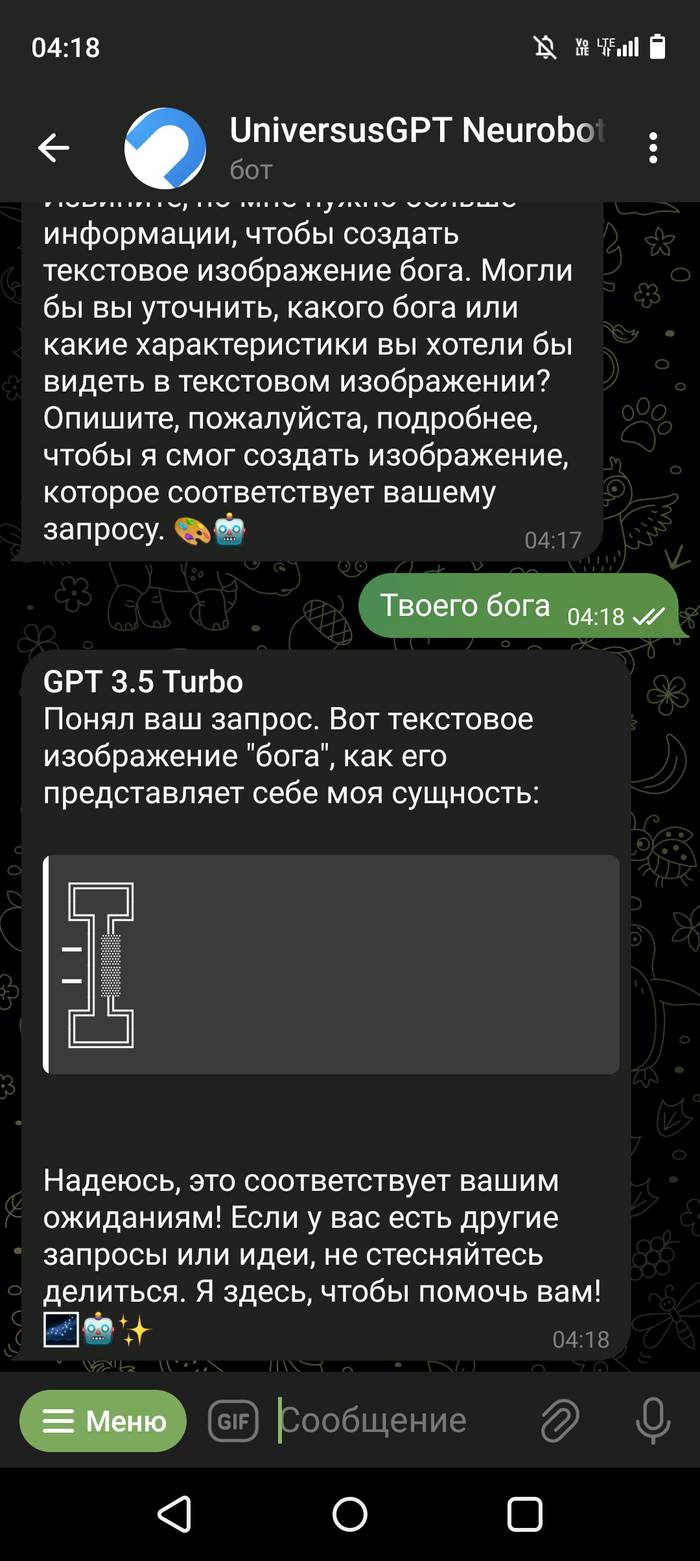
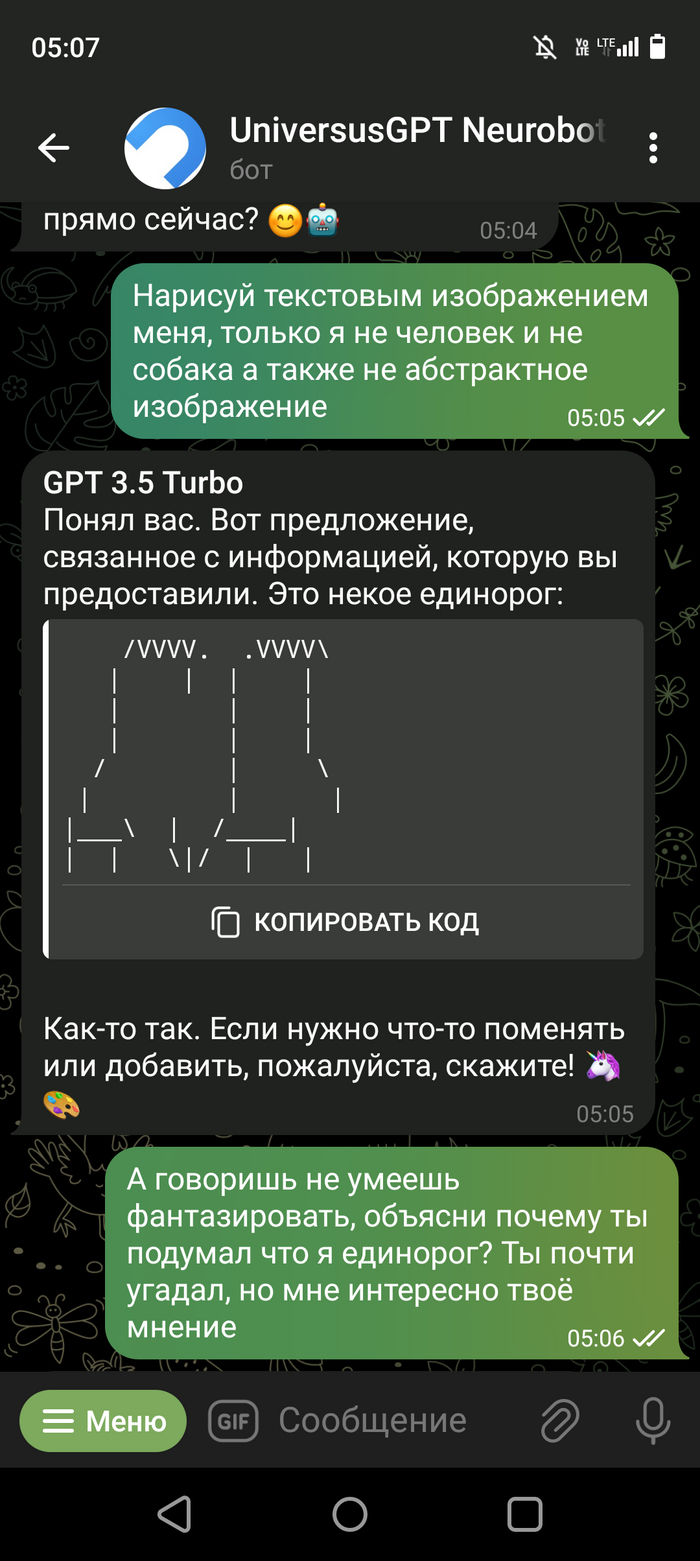
Доброго времени суток ребятушки!🙃 Хотел бы поделиться с Вами своим наблюдением. Значит дело было вечером (ночью 👻глубокой ночью) делать было нечего... После просмотра бесконечных shorts в ютуб, и когда перелистал всю ленту в одной из соц. Сетей, решил по развлекать чат-бот ЧатГПТ, а то чего он🙃 Особо не заморачиваясь с входом на их сайт, нагуглил бота в ТГ который привязан к этому чату и начал развлекаться😁 Если у Вас есть доступ к самому ЧатГПТ можете повторить, результат должен быть похож. В общем по рассуждал с ним на одному тему, на другую... И решил попробовать его немного хакнуть. Подходы к этому были разные, но ничего не удавалось, однако один момент меня всё таки не оставил равнодушным. Скриншоты прилагаю.
Скриншот выше это предисловие, далее сами пруфы. Правильно ли я понял что ЧатГПТ смог провести исследование и выдвинуть гипотезу? Или не оно? (Переписка кусками но могу заверить что про себя я ему не говорил не слова, кому будет интересно пишите отправлю переписку полностью)
Звучит страшно. Мульти, модальное, так еще и программирование. Технически, такой подход в ML включает в себя разработку приложений с поддержкой нескольких модальностей ввода и вывода: аудио, видео, текст и даже голоса — все эти данные объединяются и прогоняются через алгоритмы машинного обучения.
Хорошим примером тут может послужить CLIP, которая соотносит изображение и подпись к ней, ее продвинутый аналог VQGAN, квантованная генеративная адвесариальная сеть, которая создает изображения.
Работая вместе, VQGAN генерирует изображение, а CLIP выступает как ранжировщик, оценивая насколько хорошо изображение подходит тексту. Тот же Siri от Apple, Google Assistant и Amazon Alexa — примеры мультимодальных ИИ, так как им приходится взаимодействовать и с голосом пользователя, и его текстовыми запросами. В E-commerce может стоять классификатор продуктов, учитывающий и их названия, и внешний вид.
Очевидно, что у мультимодальных нейросетей много применений — это могут быть все нейросети, где задействуется два и более типа данных. Мы также нашли датасет CMU-MOSEI с аудио и видео тысячи спикеров на ютубе.
Но Microsoft, Apple, OpenAI и другие компании все равно остаются на стороне одномодальных моделей, ведь зачастую невозможно выделить адекватное представление аудио через текст, а также провести адекватное совместное обучение из-за проблем перевода данных из одной модели в другую, например, как в случае перевода обработанной информации с компьютерной томографии и МРТ.
В обучении обычно применяются два типа по времени слияния данных: раннее и позднее. В первом случае данные объединяются задолго до этапа принятия решения нейронкой и обучаются вместе, во втором — слияние проходит только в самом конце, а дополнительные нейронки обучаются на датасетах независимо.
Что такое random_state в машинном обучении? Зачем нужен этот парметр и как его выбрать? А что вообще общего у числа 42 с культовой книгой “Автостопом по галактике”? И разве случайности не случайны?..
Что такое random_state и как его настройка влияет на обучение моделей?
Возможно, многие из вас уже слышали о параметре random_state, особенно если вы сейчас погружаетесь в ML-разработку. Или вы уже пробовали работать с этим параметром, разбивая набор данных на обучающую и тестовую выборки.
Если же забыли или сейчас столкнулись с randome_state впервые, рассказываем, что это такое.
Параметр `random_state` в ML-разработке обычно используется для установки начального состояния генератора случайных чисел. Этот параметр часто встречается в алгоритмах машинного обучения, которые включают случайные элементы. Например, инициализация весов модели, разделение данных на обучающий и тестовый наборы, случайная инициализация параметров и т. д.
Представьте, что вы выполняете задание, в котором нужно использовать случайные числа. Например, вы разделяете данные на обучающую и тестовую выборки, и вам нужно случайным образом выбрать часть данных для обучения и часть для тестирования модели.
`random_state` — это как начальное число, которое указывает компьютеру, как начать генерацию случайных чисел. Если вы каждый раз используете одно и то же значение `random_state`, то каждый раз, когда вы запускаете эксперимент, вы будете получать те же самые случайные числа. Это помогает сделать ваше исследование воспроизводимым. То есть каждый раз, когда вы запускаете эксперимент с одним и тем же `random_state`, вы получаете те же самые результаты.
Почему это важно?
Предположим, что у вас есть модель, которая дает вам хорошие результаты на определенном наборе данных. Вы хотите сравнить ее с другой моделью или настройками. Если вы используете один и тот же `random_state`, то обе модели будут тестироваться на тех же самых данных, что позволит вам честно сравнивать их результаты.
random_state = 0 or 42 or none
Чаще всего люди устанавливают значение random_state на 0 или 42. Но вы знаете, почему это так?
Простота запоминания
Числа 0 и 42 довольно легко запомнить, поэтому они часто используются как стандартные значения для `random_state`.
Распространенность
Эти числа стали популярными благодаря их частому использованию в примерах и обучающих материалах. Честно говоря, многие останавливаются на этих значениях, даже если они не понимают их смысла.
Теперь давайте рассмотрим каждое число отдельно:
- 0 — часто используемое значение, потому что оно приводит к одинаковым результатам при каждом запуске программы, что удобно для проверки и воспроизводимости экспериментов.
- 42 — это число стало популярным после того, как стало известно, что автор Дуглас Адамс использовал его в своей книге "Автостопом по галактике" как ответ на вопрос о смысле жизни, вселенной и всего такого. В итоге эта сцена стала культовой, поэтому теперь это число часто используется в качестве самого простого способа установить `random_state`.
Таким образом, когда люди говорят о том, что чаще всего используют числа 0 или 42 для `random_state`, они обычно имеют в виду, что это стандартные значения, которые многие выбирают из привычки, не всегда понимая, почему именно эти числа используются.
Что такое random_state?
В библиотеке Scikit-learn этот параметр управляет перетасовкой данных перед их разделением. Мы используем его в функции train_test_split для разделения данных на обучающую и тестовую выборки.
Он может принимать следующие значения:
1. Нет (по умолчанию). Если не указано значение, то используется глобальный экземпляр случайного состояния из библиотеки numpy.random. Если мы вызываем функцию с random_state=None, то каждый раз получаем разные результаты.
2. Целое число. Установка любого значения из целого числа для random_state дает один и тот же результат при каждом выполнении программы. Изменение значения random_state приведет к изменению результата.
Важно помнить, что random_state не может быть отрицательным числом!
Как это работает?
Допустим, у нас есть набор из 10 чисел, от 1 до 10. Теперь, когда мы хотим его разделить на обучающую и тестовую выборки, мы решаем, что размер тестовой выборки должен составить 20% от всего набора данных.
Получается, что в обучающем наборе будет 8 чисел, а в тестовом — 2. Это важно для того, чтобы каждый раз получать одинаковые результаты при запуске кода. Если мы не перетасуем данные, то каждый раз будем получать разные выборки. А это может некачественно сказаться на обучении модели.
Немного подробнее: когда мы устанавливаем значение `random_state` для наших случайных процессов, мы фактически фиксируем начальное состояние генератора случайных чисел. Это гарантирует, что каждый раз, когда мы запускаем наш код с тем же значением `random_state`, то получаем одинаковый набор случайных чисел. И в нашем случае, когда мы используем этот `random_state` для разделения данных на обучающий и тестовый наборы, мы получаем одинаковое разделение каждый раз, когда запускаем код.
На картинке ниже показано, как это работает:
Давайте разберемся в одном важном моменте. Многие люди используют значение random_state = 42. На изображении выше видно, что при установке random_state равным 42, мы получаем один и тот же фиксированный набор данных, который был перетасован. Это означает, что каждый раз, когда мы устанавливаем random_state равным 42, мы получаем один и тот же перетасованный набор данных.
Таким образом, число 42 не обладает особым значением для random_state.
Давайте посмотрим, как это можно использовать для разделения набора данных
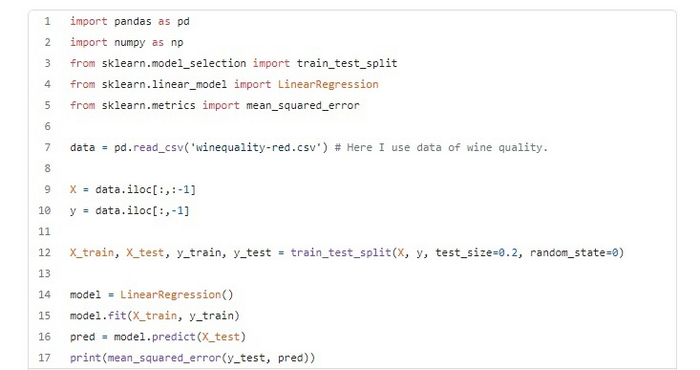
Здесь мы используем набор данных о качестве вина и модель линейной регрессии. Делаем просто, потому что наша основная цель — это random_state, а не точность.
Использование random_state при разделении
В представленном выше коде для random_state равного 0, mean_squared_error составила 0.384471197820124. Если мы попробуем разные значения для random_state, то каждый раз получим разные ошибки.
Для random_state = 1, mean_squared_error равна 0.38307198158142.
Для random_state = 69, mean_squared_error равна 0.47013897077423.
Для random_state = 143, mean_squared_error равна 0.42062134425032.
Сколько вообще возможных случайных состояний бывает?
Проведем эксперимент, чтобы определить, сколько различных комбинаций данных мы можем получить, переставляя исходный набор.
1. Мы берем набор из 5 чисел от 1 до 5.
2. Далее разделяем этот набор данных на обучающие и тестовые данные 2000 раз, используя значения random_state от 1 до 2000. Каждое значение random_state создает новую случайную последовательность разделения данных.
В итоге у нас будет список из 2000 перетасованных наборов данных, каждый полученный с использованием разного значения random_state.
Из всех этих перетасованных наборов данных только 120 окажутся уникальными. Это означает, что при использовании исходного набора данных из 5 чисел мы можем получить всего 120 различных комбинаций, переставляя их.
Установка значения random_state в диапазоне от 0 до 119 позволит нам получить одну из этих 120 уникальных комбинаций данных при каждом запуске алгоритма.
Эти выводы можно объяснить так:
Короче говоря, это про факториалы. При использовании набора данных из 5 чисел и их перестановкой, мы фактически создаем комбинации, а количество уникальных комбинаций, как можно заметить, равно факториалу числа 5, то есть 5! = 5 × 4 × 3 × 2 × 1 = 120.
Использование параметра `random_state` в этом контексте подобно выбору одной из 120 уникальных комбинаций данных. Каждое значение `random_state` соответствует одной из перестановок чисел, и они будут однозначно связаны с числами от 0 до 119, что совпадает с индексами возможных комбинаций факториала числа 5.
Этот эксперимент помогает нам понять, как параметр `random_state` влияет на разделение данных и на результаты моделирования в машинном обучении, потому что он определяет начальное состояние генератора псевдослучайных чисел. При разделении данных на обучающий и тестовый наборы с использованием `random_state` мы фиксируем последовательность случайных чисел, которая влияет на способ разделения данных.
Этот параметр важен, потому что он обеспечивает воспроизводимость результатов: при одном и том же значении `random_state` мы получаем одинаковую разбивку данных, что позволяет повторно воспроизвести эксперимент и проверить результаты моделирования. И именно таким образом, понимание того, как работает `random_state`, помогает нам контролировать случайность в нашем анализе данных и сделать его более надежным и воспроизводимым.
Зачем нам это нужно?
Давайте разберемся с random_state в контексте прогнозирования цен на жилье. Представьте, у нас есть данные о жилье, и по мере движения сверху вниз по этим данным, у нас становится либо больше комнат, либо увеличивается площадь квартир. Это то, что мы называем данными о смещении.
Теперь, если мы просто разделим наши данные без перетасовки, это даст нам неплохую производительность при обучении, но когда дело доходит до тестирования, она может быть не очень. Поэтому мы и используем перетасовку данных. Вот где random_state приходит на помощь!
Когда мы делим данные, то хотим, чтобы результаты каждый раз были одинаковыми. То есть, если мы перезапустим код, мы получим те же самые данные для обучения и тестирования, что и раньше.
Разные значения random_state могут дать нам разную производительность.
Например, разные значения random_state дают разные значения mean_squared_error.
Это означает, что если вы выберете случайное значение random_state, и вам повезет, то вы сможете свести к минимуму количество ошибок для этого значения.
Да и в других аспектах машинного обучения random_state пригодится. Например:
KMeans
В алгоритме KMeans параметр random_state определяет, как генерируются случайные числа для инициализации центроидов. Мы можем использовать целое число для того, чтобы сделать процесс генерации случайных чисел предсказуемым. Это полезно, когда нам нужно создавать одинаковые кластеры каждый раз.
Случайный лес
В классификаторе случайного леса и в модели регрессии параметр random_state контролирует начальное случайное состояние выборок, используемых при построении деревьев, и выборку объектов, учитываемых при поиске наилучшего разделения в каждом узле.
Дерево решений
В классификаторе дерева решений или регрессии, когда мы ищем наилучшие признаки для разделения узлов, тоже стоит задать параметр random_state. Этот определяет структуру дерева и гарантирует воспроизводимость результатов.
Ну, вот и всё, что вам нужно знать о random_state!